Una introducción
El objetivo de la inteligencia artificial es el permitirle a las computadoras desarrollar habilidades que típicamente requieren inteligencia humana.
El Machine learning o aprendizaje automático es una sub-rama de la inteligencia artificial, podría decirse que el Machine Learning es el estudio y aplicación de cierto tipo de técnicas con las cuales es posible desarrollar inteligencia artificial. La razón por la cual se le dice aprendizaje automático es porque este tipo de aplicación permite que las computadoras aprendan sin necesidad de intervención humana.
Esta sub-rama contiene otras sub-ramas como el aprendizaje reforzado, el aprendizaje no supervisado, el aprendizaje semi-supervisado, y el aprendizaje supervisado. Sobre este último tratará este artículo.
¿Qué es?
El aprendizaje supervisado es una modalidad del Machine Learning donde la computadora aprende a reconocer patrones partir de los datos ingresados, etiquetados y clasificados por un ser humano. Para entregar algún tipo de resultado específico deseado. Este tipo de aprendizaje es el más sencillo y más adoptado en todo el mundo.
¿Para qué se utiliza?
El aprendizaje supervisado es utilizado por bancos de todo el mundo para la detección de transacciones fraudulentas.
También es utilizado en el ámbito de la medicina para detectar cáncer de piel y otro tipo de enfermedades.
El año 2019, en el primer challenge de la plataforma AiUteChallenge se utilizó para predecir la probabilidad de abandono de distintos estudiantes de UTEC.
¿Cómo funciona?
El aprendizaje supervisado funciona a través de ejemplos, se le entrega a la máquina un conjunto de datos etiquetados para que aprenda a reconocer patrones, de forma de detectarlos al ver datos nuevos sin etiquetar. El concepto de etiquetar se explicará más adelante.
El aprendizaje supervisado tiene dos modalidades principales para ser utilizado, estas son la regresión y clasificación.
Regresión
La regresión es una de las modalidades más simples de Machine Learning, lo que significa que también es una de las más rápidas, consume pocos recursos y su funcionamiento es mucho más transparente y fácil de entender, por lo cual es una de las modalidades más accesibles para principiantes.
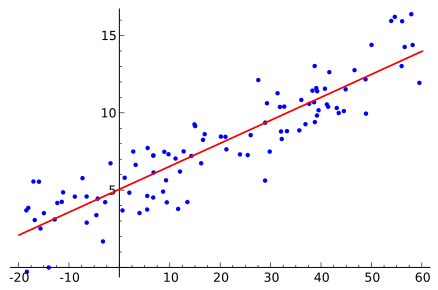
La regresión consiste en darle datos a una máquina para que esta intente comprender la relación entre distintas variables, de esta forma es posible predecir, pronosticar y encontrar resultados. Un buen ejemplo sería predecir la calificación que obtendrá un estudiante en un examen a partir de sus horas de estudio y su asistencia a clases.
Los ejemplos de la vida real pueden ser una buena manera de aprender conceptos, para lo cual tenemos la siguiente gráfica.
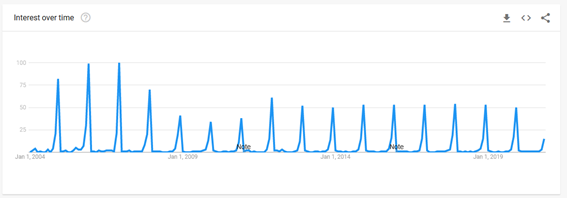
La anterior gráfica obtenida a través de Google Trends muestra las búsquedas relacionadas a la canción “All I Want For Christmas is You” (“Todo lo que quiero para navidad eres tú” en español) de Mariah Carey, una de las canciones navideñas más famosas de Estados Unidos.
Cada pico de interés corresponde al mes de diciembre de cada año, la gráfica llega hasta el día 2 de diciembre del 2020. Si alguien pidiera que dibujaras la continuación de esa gráfica ¿Qué harías? Lo más probable es que dibujaras otro pico en el mes de diciembre que bajara tan rápido como subió ¿Por qué es tan obvia esta conclusión? Porque lo mismo sucede todos los años.
Este tipo de razonamiento sencillo es bastante similar a como funciona una regresión, el cerebro humano instintivamente es capaz de encontrar la relación entre las variables de tiempo y la popularidad de esta canción.
La regresión consiste en otorgarle a una computadora estas mismas capacidades de relacionar variables a través de matemática, evitando así los posibles sesgos y errores humanos. Sin mencionar el hecho de que una máquina puede manejar una mayor cantidad de variables y datos.
Para lograr esto hay una gran variedad de técnicas de regresión, estas son algunas de ellas:
- Regresión Lineal (Linear Regression)
- Regresión Logística (Logistic Regression)
- Regresión de Ridge (Ridge Regression)
- Regresión de Lasso (Lasso Regression)
- Regresión polinómica (Polynomial Regression)
- Regresión Lineal Bayesiana (Bayesian Linear Regression)
Clasificación
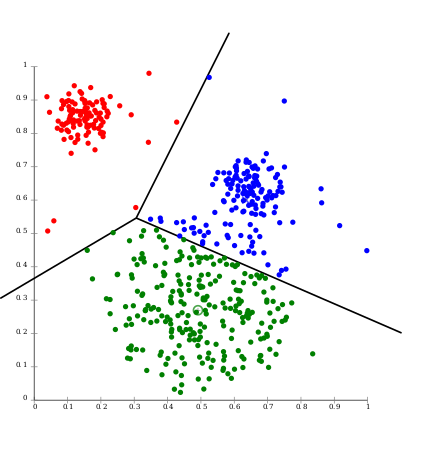
Para explicar cómo funciona la clasificación usaremos como ejemplo el desafío de 2019 del aiutechallenge.
Este desafío constaba de predecir la probabilidad de que un estudiante abandonara sus estudios en UTEC a partir de varios tipos de datos, usaremos una versión simplificada de ejemplo.
Supongamos que tenemos una planilla de datos anónimos de distintos estudiantes. Esta planilla vamos a dividirla en dos secciones, una sección para entrenar a la computadora, la cual estará etiquetada y otra sección para evaluarla, la cual no tendrá etiquetas. Similar a como en una clase un docente le entrega a los estudiantes las soluciones de los ejercicios de práctica pero entrega estas durante un examen.
La siguiente tabla sería la sección de entrenamiento de la planilla, decimos que está etiquetada. Las etiquetas se encuentran en la última columna, la cual especifica si el estudiante abandonó o no, la etiqueta de cada fila entonces es este valor binario (ya que solo puede tener dos valores: “si” o “no”). Las columnas de datos que no corresponden a la etiqueta son conocidas como preguntas.
|
Nº |
Edad |
Carrera |
Trabaja (Si/no) |
Horas de trabajo semanales |
Promedio de notas |
Semestres cursados |
¿Abandonó? (Si/no) |
|
1 |
24 |
ILOG |
Si |
20 |
4,60 |
5 |
No |
|
2 |
20 |
IMEC |
No |
0 |
3,05 |
3 |
No |
|
3 |
19 |
IEE |
No |
0 |
2,79 |
2 |
Si |
|
4 |
33 |
TJMC |
Si |
60 |
2,10 |
1 |
Si |
|
… |
… |
… |
… |
… |
… |
… |
… |
|
800 |
36 |
TMSPL |
Si |
30 |
3,36 |
6 |
No |
Esto es entonces un problema de clasificación donde tenemos dos conjuntos, por un lado tenemos el conjunto de aquellos que abandonan y por otro tenemos el conjunto de aquellos que no abandonan su carrera. La idea es que luego de que la máquina haya sido entrenada podamos mostrarle los datos de evaluación los cuales no están etiquetados y que esta nos devuelva resultados precisos la mayoría de las veces.
Se dice que en el aprendizaje supervisado las salidas de datos son conocidas o esperadas, esto implica que sabemos qué tipo de respuesta podemos obtener de la inteligencia artificial. En este caso sabemos que obtendremos un número, una probabilidad entre 0% y 100% de que ese estudiante pertenezca a un conjunto o a otro.
La idea entonces es que una vez le demos los resultados sin etiquetar a la máquina, esta nos devuelva un resultado similar a este:
|
Nº |
Edad |
Carrera |
Trabaja (Si/no) |
Horas de trabajo semanales |
Promedio de notas |
Semestres cursados |
Probabilidad de abandono |
|
1 |
36 |
ILOG |
Si |
20 |
4,67 |
7 |
15,34% |
|
2 |
20 |
IMEC |
No |
0 |
2,01 |
1 |
78,02% |
|
3 |
42 |
IEE |
Si |
50 |
1,56 |
1 |
90,35% |
|
4 |
18 |
TJMC |
Si |
6 |
2,60 |
2 |
22,24% |
|
… |
… |
… |
… |
… |
… |
… |
… |
|
200 |
24 |
TMSPL |
No |
0 |
4,36 |
3 |
5,45% |
La clasificación es utilizada en gran cantidad de ámbitos para tareas como reconocimiento de imágenes, reconocimiento de lenguaje, sistemas de recomendación, entre muchos otros.
También puedes participar del challenge AIA2C: AI applied 2 Cybersecurity donde es necesario clasificar diferentes tipos de eventos en la red.
